Research Workflow¶
After introducing general steps of conducting research, in this section, we will get into the details of Decision Strategy and Research Workflow.
Figure 1 combines all the previously discussed processes and flowcharts of the Execution Flow, and gives an overview of the entire research workflow. The diagram can be separated into two main processes, Main Research Line and Hacking Workflow. Additionally, there are several Selection→Decision sequences spread throughout the flowchart (highlighted in red) that helps the Researcher to navigate between stages, and make certain decisions.
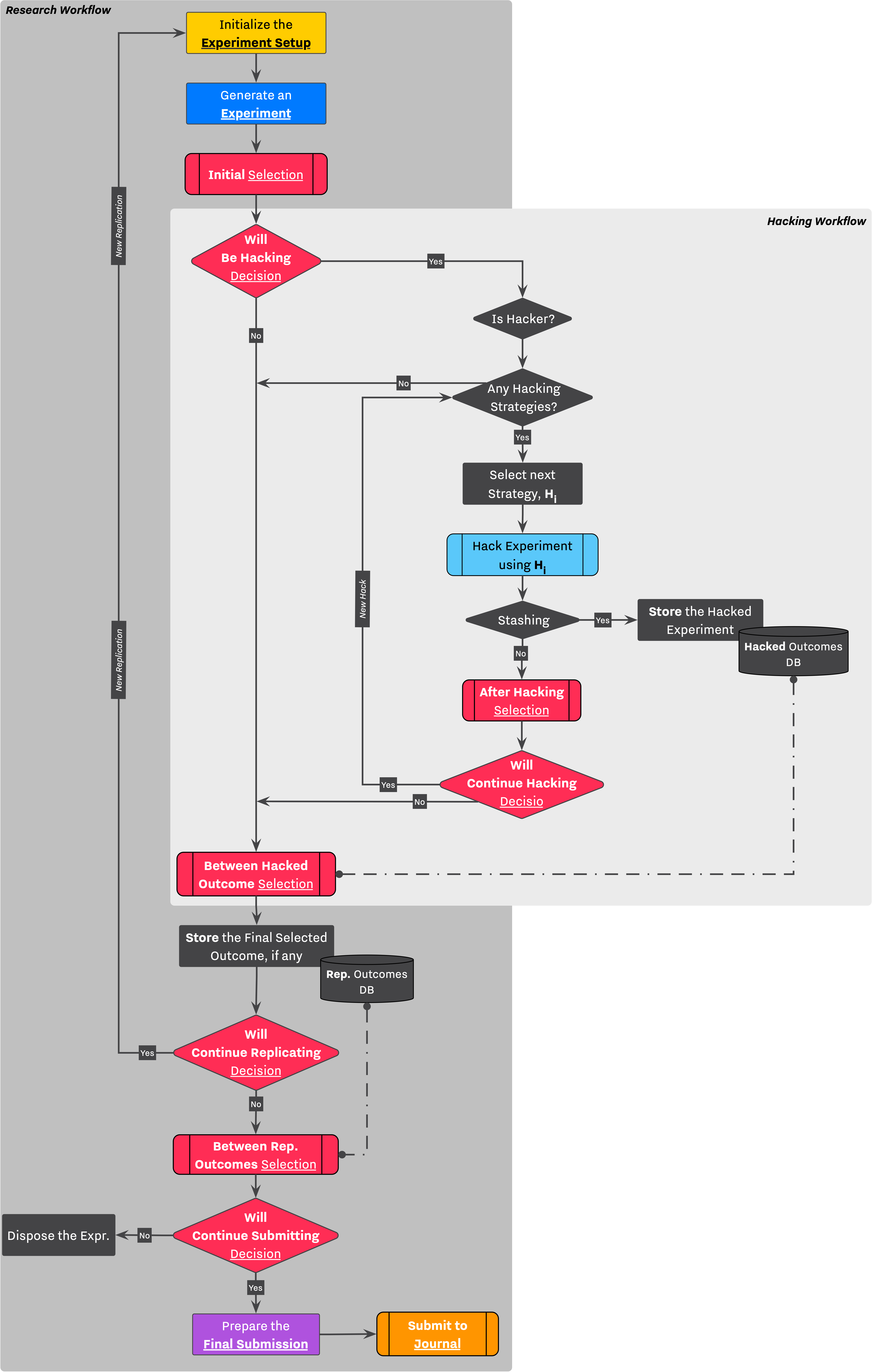
This section will walk you through each process and discuss each step in more detail.
Initial Stage¶
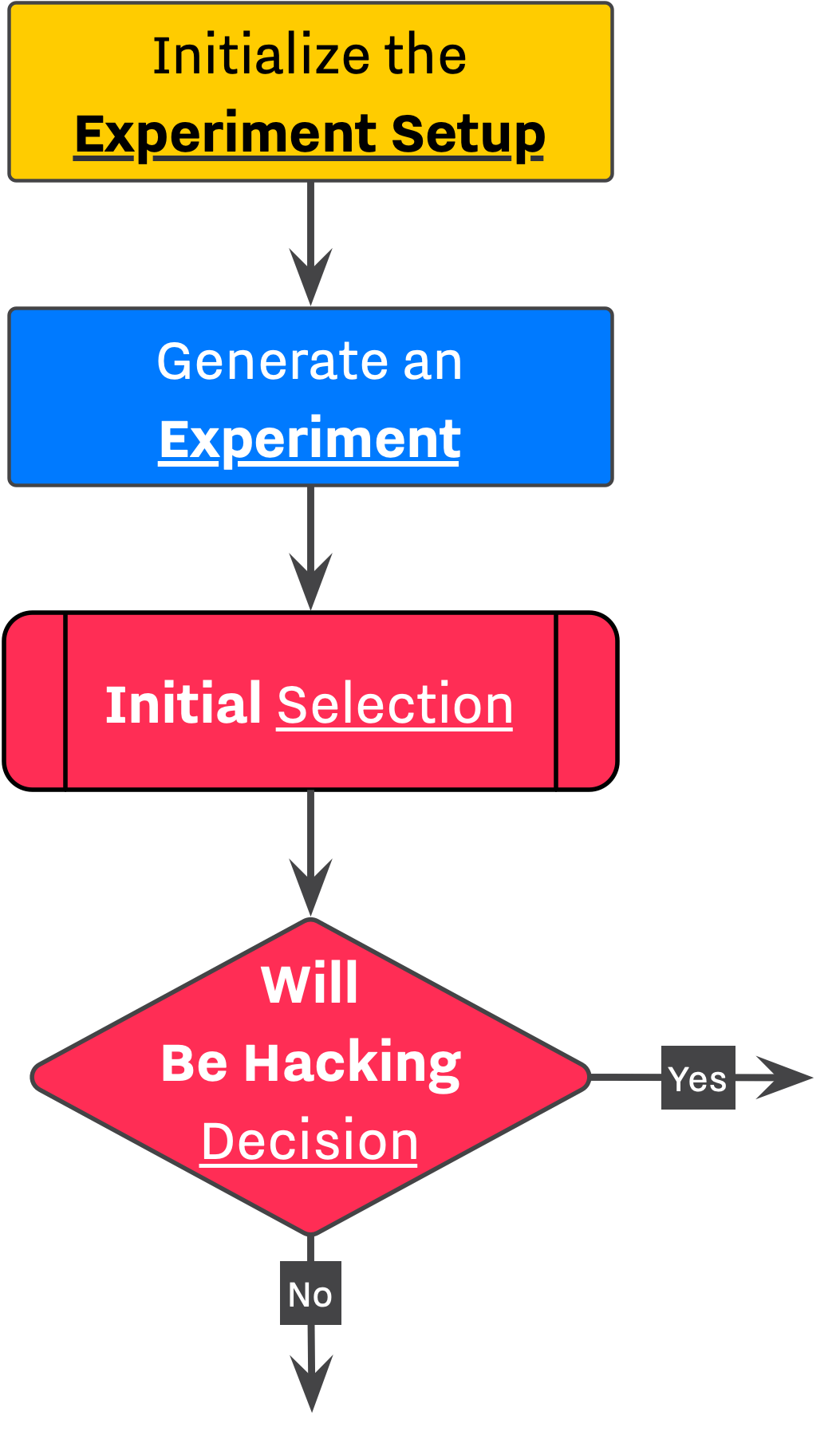
As discussed in the Design section, research starts by initializing the Experiment Setup and thereafter preparation of the Experiment which consists of generating data, calculating statistics, running tests, calculating effects, etc.
When the Experiment is fully initialized, the Researcher is able to asses the quality of results, and select her preferred outcome among all available outcome variables across all conditions and dependent variables. This is beingdone during the first selection stage, Initial Selection. At this stage, the Researcher can query all available outcomes using specific set of rules. For example, by using ["sig", "min(pvalue)"] Policy, she will seek an outcome with minimum p-value between those that are significant.
Despite the success of failure of the Initial Selection, the Researcher decides on whether to embark on a journy of exploring QPRs. This is done at the Will be Hacking Decision stage, where the Researcher uses a chain of policies to determine her next move. For instance, if she is looking for an outcome with positive effect (ie., ["effect > 0"]) and the previously selected outcome does not have a positive effect, researcher might opt-in for applying some hacking strategies.
Hacking Workflow¶
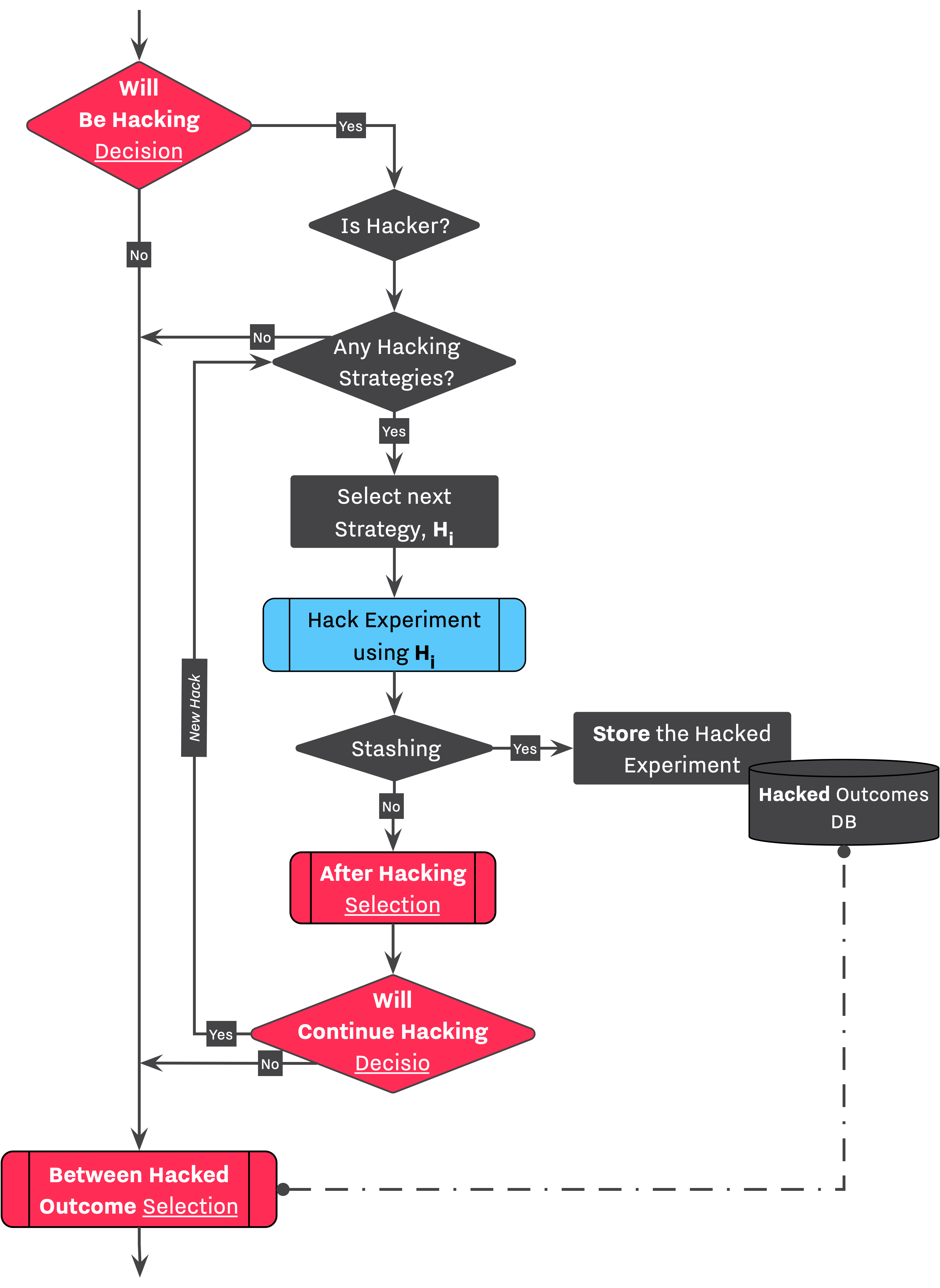
If the Researcher is not satisfied with the selected submission, and the configuration indicates that he is going to apply some QRPs, then, he continues to the Hacking Workflow stage.
In this stage, the Researcher selects the first hacking strategy from his list, H₁ and applies it on the Experiment. This process is highlighted in light blue, Hack Experiment using Hᵢ. After each QRP, researcher has a chance to collect the altered results for later investigation, we refer to this process as Stashing.
Whether the Researcher performs a stashing process, he continues to another Selection→Decision sequence where he evaluates the altered the Experiment after applying H₁. The selection procedure is defined by an another set of policy chains — After Hacking Selection — which either leads to an empty submission or an unique submission. Right after selection, researcher needs to decide whether he is going to continue the hacking procedure — Will Continue Hacking Decision. If researcher decides to continue the hacking procedure, he would then choose the next hacking strategy, Hi+1, and repeat the same process.
Stashing and Post-QRP Selection¶
Stashing policy indicates what type of outcomes should temporary be stored by the Researcher for further exploration of his results. After leaving the Hacking Workflow, the Researcher is equipped with a set of outcomes selected from his ventures into his QRP arsenal. The Researcher is being given the chance of selecting an outcome from his stashed outcome, Hacked Outcomes DB., if he finds it necessary.
In a real world scenario, this process mimic a very greedy and inconsiderate researcher who is trying everything to achieve a certain goal, ie., significance (["sig"]), and collect every modifications and outcomes to ultimately select an outcome from his stashed of altered results.
Post-QRP Decision and Replication Stage¶
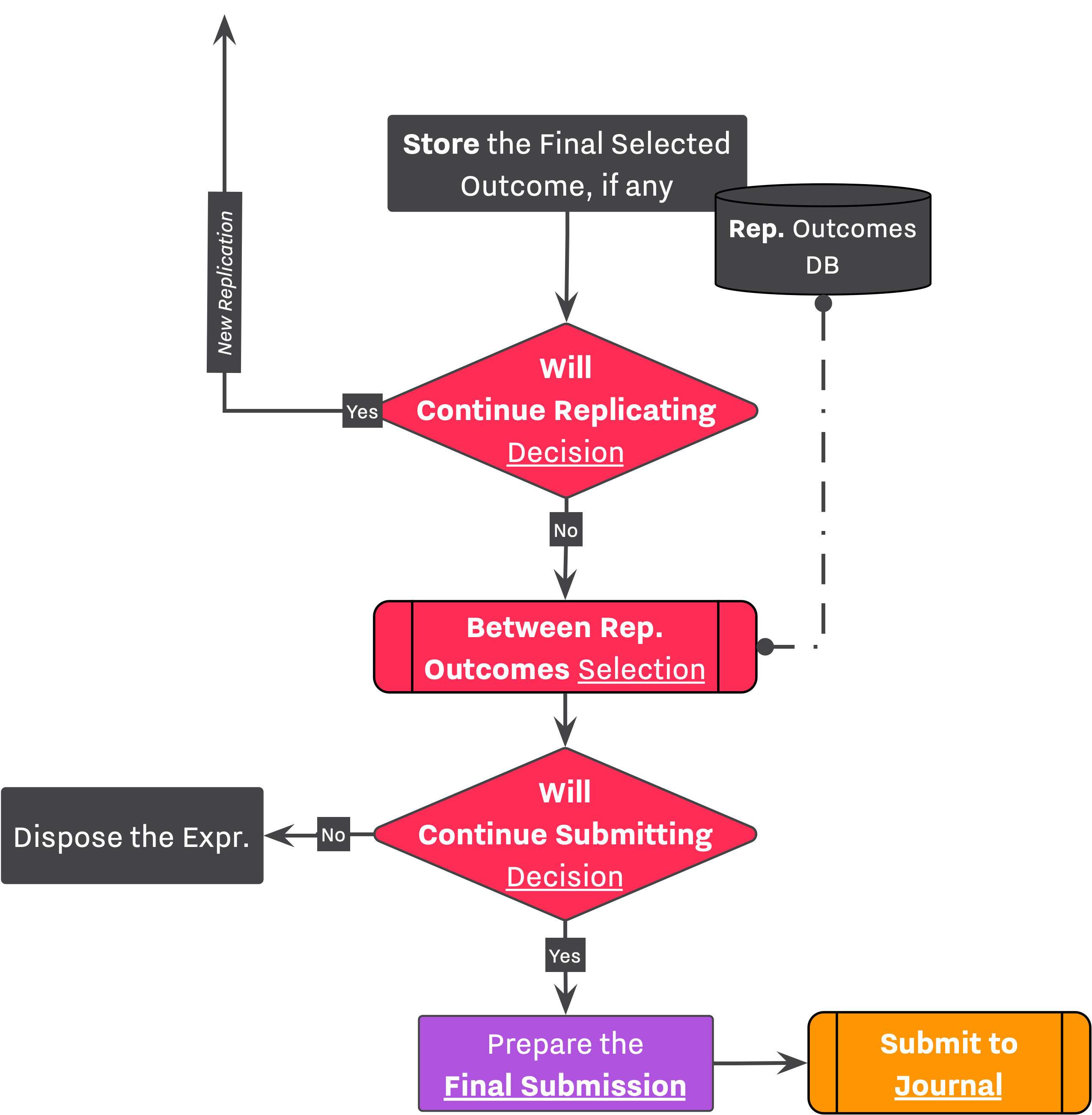
Researcher's final selected outcome, SFᵢ will be stored in an another dataset, Rep. Outcomes DB.
If researcher is intending to perform more than one replication of his research, n_reps, see configuration file. Then, he faces another decision, Will Continue Replication Decision. If the verdict is a yes, researcher stores the current selected outcome, SFᵢ, and initiates a replication of the Experiment using the parameters defined in the Experiment Setup.
After performing n_reps replication, or negative ruling of Will Continue Replicating Decision (which leads termination of the replication process), the Researcher moves to the final stage of his research. Throughout another Selection→Decision sequence, the Researcher selects an outcome among all those stored from every replications, and decides on whether he is going to submit that submission to the Journal. The final decision stage acts as researcher's final call to whether his research is good enough (in his terms) to be submitted as a manuscript to the Journal.
Finally¶
By the time that Final Submission, SF, is out of Researcher's hand and at Journal's mercy, the process of conducting research by the Researcher is finalized. At this point, the Journal decides on whether the manuscript is "publishable".