Modules¶
In the previous section, we listed main components and entities involved in the different stages of conducting research, e.g., Experiment Setup, Experiment, Researcher, Submission, and Journal. In our model, each component is a semi-independent entity while the whole system and its processes (i.e. conducting scientific research) are defined through their interactions.
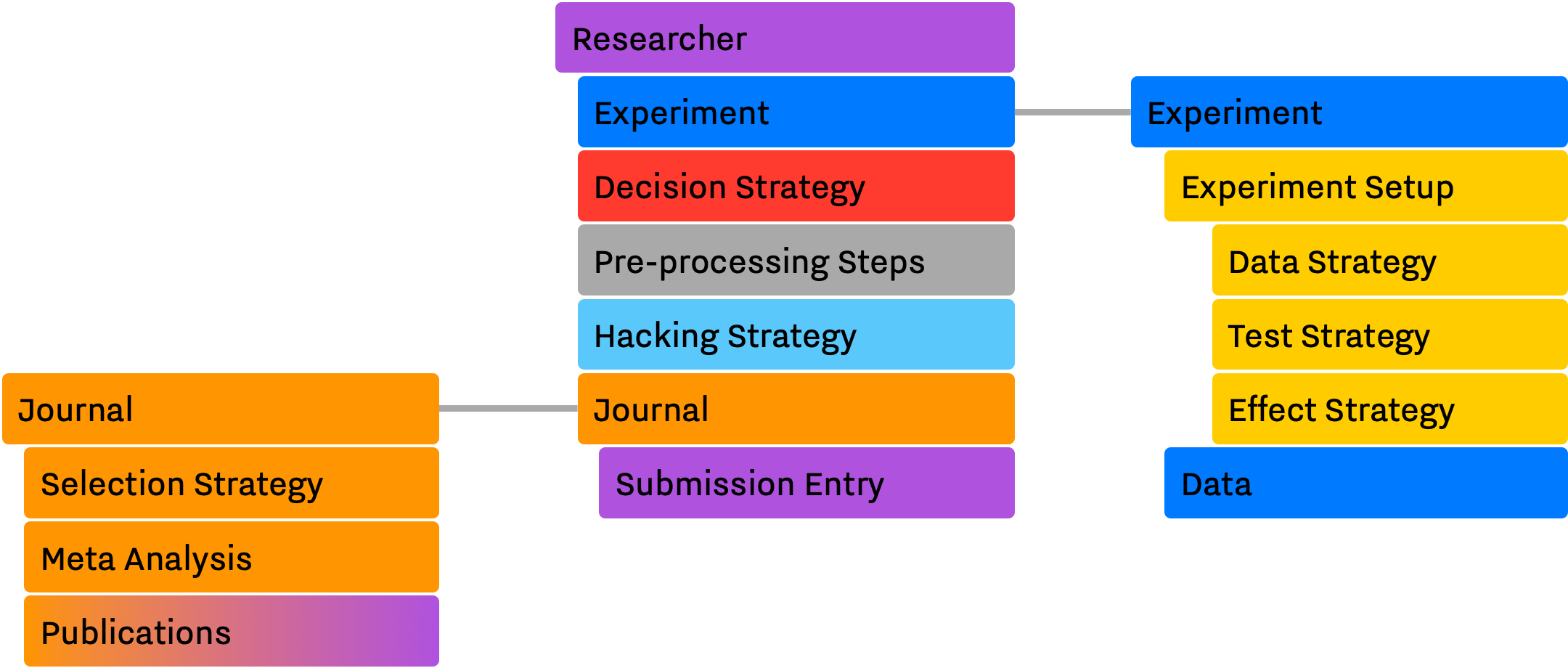
One of our main design goals with SAM was to achieve a level of flexibility where we could change different aspects of each component. In order to achieve this, we decoupled the system to smaller — but conceptually meaningful — routines and entities. Figure 1. shows these components, and their dependencies and interactions with each other.
Attention
Throughout this document, we use the color assigned to each module in Figure 1. to refer to them in different sections.
This section describes the design principles behind each component, what they model in the real world and how they work and interact with each others to collectively simulate the process of producing scientific research.
SAM's Main Components¶
SAM consists of 3 main components, Experiment, Researcher and Journal. Each component mimics one of the subprocesses or entities that are discussed in the Introduction The list below briefly introduces each component alongside their roles.
- The Experiment comprises of several parts, each dealing with different aspects of a research, e.g., setup, data, test, effect.
- Experiment Setup holds the specification of the design. The Researcher can only set these parameters once, at the start of an experiment. In fact, the Experiment Setup implementation simulates the concept of pre-registration.
- Data Strategy is a routine used to generate data based on specified parameters in the Experiment Setup.
- Test Strategy is the statistical method of choice in the Experiment Setup for testing the result of an Experiment.
- Effect Strategy defines the method of calculating effect sizes in an Experiment.
- Experiment Setup holds the specification of the design. The Researcher can only set these parameters once, at the start of an experiment. In fact, the Experiment Setup implementation simulates the concept of pre-registration.
- The Researcher module imitates the behaviors of a researcher, including possible questionable research practices conducted by him/her. The Researcher defines the Experiment Setup, generates and collects data, runs the statistical test, decides whether to preform any QRPs, prepares the Submission record, and finally submits its finding(s) to the Journal of her/his choice.
- Decision Strategy is the underlying logic and steps of performing the research, as well as selecting and reporting specific variables as the primary outcome in an Experiment.
- Hacking Strategy is a list of questionable research practices in the researcher's arsenal. In the case where the researcher decides to hack his/her way to finding significant results, he/she can use these methods.
- The Journal is a container of publications. The Journal keeps track of its publications and can utilize different metrics to adapts its selection strategy.
- Selection Strategy is the internal algorithm by which the journal decides whether a submission will be accepted.
- Submission is a concise report, acting as a scientific paper, or a manuscript that it is going to be submitted for review to the Journal.
Note
Unlike a real scientific journal that covers a wide range of research tracks, SAM's Journal in its current implementation assumes that all submitted publications are from one research track. In other words, SAM's journals are mainly acting as a pool for related studies ready to be analyzed using meta-analyses methods.
The rest of this section discusses each component properties and rule in more details, and more information about each component can be found in their dedicated pages.
Experiment¶
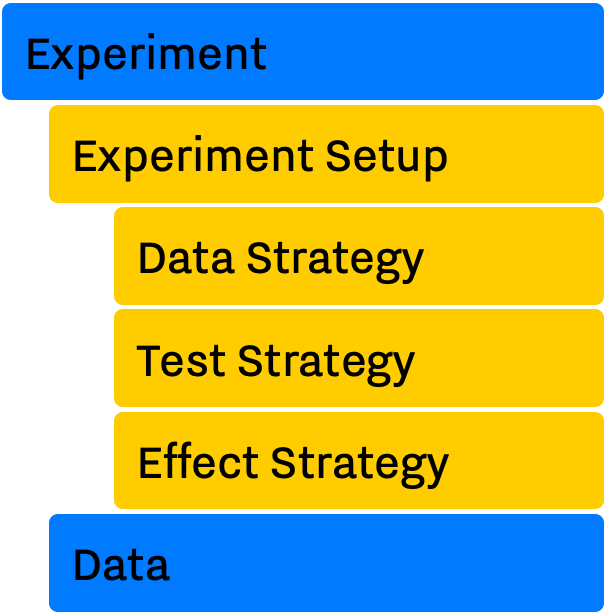
As mentioned, an Experiment object acts as an umbrella for everything related to an actual experiment. This includes metadata (a.k.a Experiment Setup), raw data, method/model for generating the data, e.g., Linear Model, methods of testing the hypothesis, and calculating the effect. The Researcher object has complete control over every aspect of an Experiment with one exception: it can only read and not change the Experiment Setup object. This is an important factor when later on we discuss the concept of pre-registration.
The main components of the Experiment are:
- Experiment Setup
- Data, an object containing actual data points
Experiment Setup¶
After the initialization phase, SAM treats the Experiment Setup object as a read-only object. During the initialization phase, SAM initializes and randomizes the Experiment Setup based on given parameters. Thereafter, Experiment Setup will stay intact in the code and will be used as a reference point in different stages.
The main components of the Experiment Setup are:
- Design Parameters
- Number of conditions
- Number of dependent variables
- Number of observations per group
- Data Strategy
- Test Strategy
- Effect Strategy
Data Strategy¶
Data Strategy acts as the population of the study, i.e., data source. In most cases, an instance of the Data Strategy object uses a statistical model to sample data points and populates the Data object of the Experiment.
Moreover, with certain p-hacking methods, e.g., optional stopping, the data strategy will be used to generate extra data points as requested by the optional stopping.
Available data strategies are:
- Linear Model
- Graded Response Model
- Latent Model (under development)
Test Strategy¶
TestStrategy provides a routine for testing the hypothesis. TestStrategy can access the entire Experiment object but often it is restricted to only modifying relevant variables, e.g., pvalue, statistics, sig.
Test Strategies already implemented:
- T-Test
- F-Test
- Yuen T-Test
- Wilcoxon Test
Effect Strategy¶
EffectStrategy defines a method of calculating the magnitude of effect between two experimental groups.
Available effect strategies:
- Mean Difference
- Cohen's D
- Hedge's G
- Odd Ratio
Journal¶

In SAM, a Journal is a container for accepted publications. Journal is designed to mimic the reviewing process. Therefore, it uses an arbitrary algorithm for deciding whether a submission will be accepted.
The Journal's components are:
- Selection Strategy
- Accepted List, ie., Publications List
- Rejected List
- Meta-analytic Methods
- Meta-analytic Results
Selection Strategy¶
Selection Strategy implements the logic behind accepting or rejecting a submission. The simplest algorithms are based on p-values and their decision is a simple threshold check. However, more elaborate selection strategies incorporate different metrics or criteria (e.g., pre-registration, sample sizes, or meta-analysis) into their final decision. For instance, if appropriate, a journal can have an updated estimation of the effect size from its current publications pool and use that information to accept or reject new submissions.
List of available selection strategies are:
- Significant Selection
- Random Selection
- Free Selection
Submission¶
A Submission is a container, created by the Researcher and provided to the Journal. It provides a simple interface between Journal, Experiment and Researcher objects. In fact, a Submission resembles a manuscript when it is at the hand of the researcher and a publication after being accepted by the journal.
After performing the test and choosing an outcome variable, the Researcher puts together a report containing necessary information for the Journal to decide whether to accept or reject the submitted finding(s). This representation allows us to mimic several important concepts related to publication habits, e.g., the file-drawer effect, pre-registration.
Researcher¶

The Researcher object is the main player in the simulation. It uses the Experiment Setup to prepare the Experiment and send the final outcome to the Journal for the reviewing process.
After the initialization of the Experiment Setup, the Researcher prepares the Experiment object by collecting data via the Data Strategy, tests the hypothesis via the Test Strategy, and calculates the effect sizes using the Effect Strategy. Then, if configured to, it applies different QRPs on the Experiment and hacks its way to a satisfactory result. In the end, the researcher prepares a Submission record and sends it to the Journal for review. This process is discussed in more detail in Execution Flow and Research Workflow.
Decision Strategy¶
Decision Strategy models the decision making process during the research process. The Researcher relies on the verdict of the decision strategy two main ways, Selection and Decision policies.
- Selection policies are used by Researchers to filter and select an outcome from a group of outcomes. For instance, if a Researcher only considers outcomes with significant p-values satisfactory, a selection policy will help her to only select for those among all available outcomes.
- Decision policies process, are used to make certain decisions during the research process. For instance, whether a researcher should start applying QRPs on an experiment, or whether it should submit the final submission to the journal.
Selection and Decision policies follows each other in this order. In most cases, a decision should be made about the already selected outcome. For instance, as the researcher applies a QRP on an experiment, he uses a Selection policy to look for his preferred outcome, then, he needs to make a decision whether he is going to continue with the next QRP or if he finds the selection satisfactory. The notion of satisfactory outcome will be decided by a Decision policy. As we will discuss later, we’ll be able to define various criteria (policies) for selection and decision processes.
Some of the Selection→Decision sequences available are:
- Initial Selection Policy
- Will be Hacking Decision Policy
- each hacking strategy will end with a selection-decision of its own
- Selection
- Decision
- each hacking strategy will end with a selection-decision of its own
- Between Hacked Outcomes Selection Policies
- Will Continue Replicating Decision Policies
- Will be Submitting To Journal Decision Policy
Decision Strategy is one of the more elaborated pieces of SAM. It engages in different stages of conducting the research by researcher and different hacking strategies. This process will be clarified in Flow and Research Workflow and Decision Strategy.
Hacking Strategies¶
Hacking Strategy is an abstract representation of different p-hacking and QRP methods. The Researcher performs a hacking strategy by sending a copy of its Experiment to a chosen method. The Hacking Strategy takes control of the experiment, modifies it, (e.g., adding new values, removing values), recomputes the statistics, reruns the test, and finally returns the modified Experiment. Finally, the researcher can evaluate the hacked experiment, and select the hacked result if satisfactory.
If more than one hacking strategies are registered, The Researcher navigates through them by the logic defined in Decision Strategy and decides whether any of the hacked experiments will be used for constructing the Submission. This process will be discussed in more detail, in Decision Strategy and Hacking Strategy.
The available hacking strategies are:
- Optional Stopping
- Outliers Removal
- Subjective Outliers Removal
- Questionable Rounding
- Falsifying Data
- Fabricating Data
- Stopping Data Collection