Decision Strategies¶
Decision strategy acts as researcher's brain, and describes his/her logical steps. Its specification will be used by the Researcher to perform two fundamentals tasks, Selection and Decision. As discussed in the Design section, in most cases a Selection is followed by a Decision, directly evaluating the already selected outcome.
We will refer to this process as Selection → Decision sequence. These sequences are the building block of decision strategy. We use utilize them in several different stages of Research, and Hacking workflows in order to mimic the thought process of the Researcher and guide him throughout his research.
As researcher needs to perform several selections and decisions during her course of research, each selection and decision is defined separately in the configuration file. Figure 1 shows a simplified version of research workflow by only highlighing Selection and Decision stages. The diagram also replaces logical names with their parameter names counterpart as they are lsited in decision_strategy section of configurtion file.
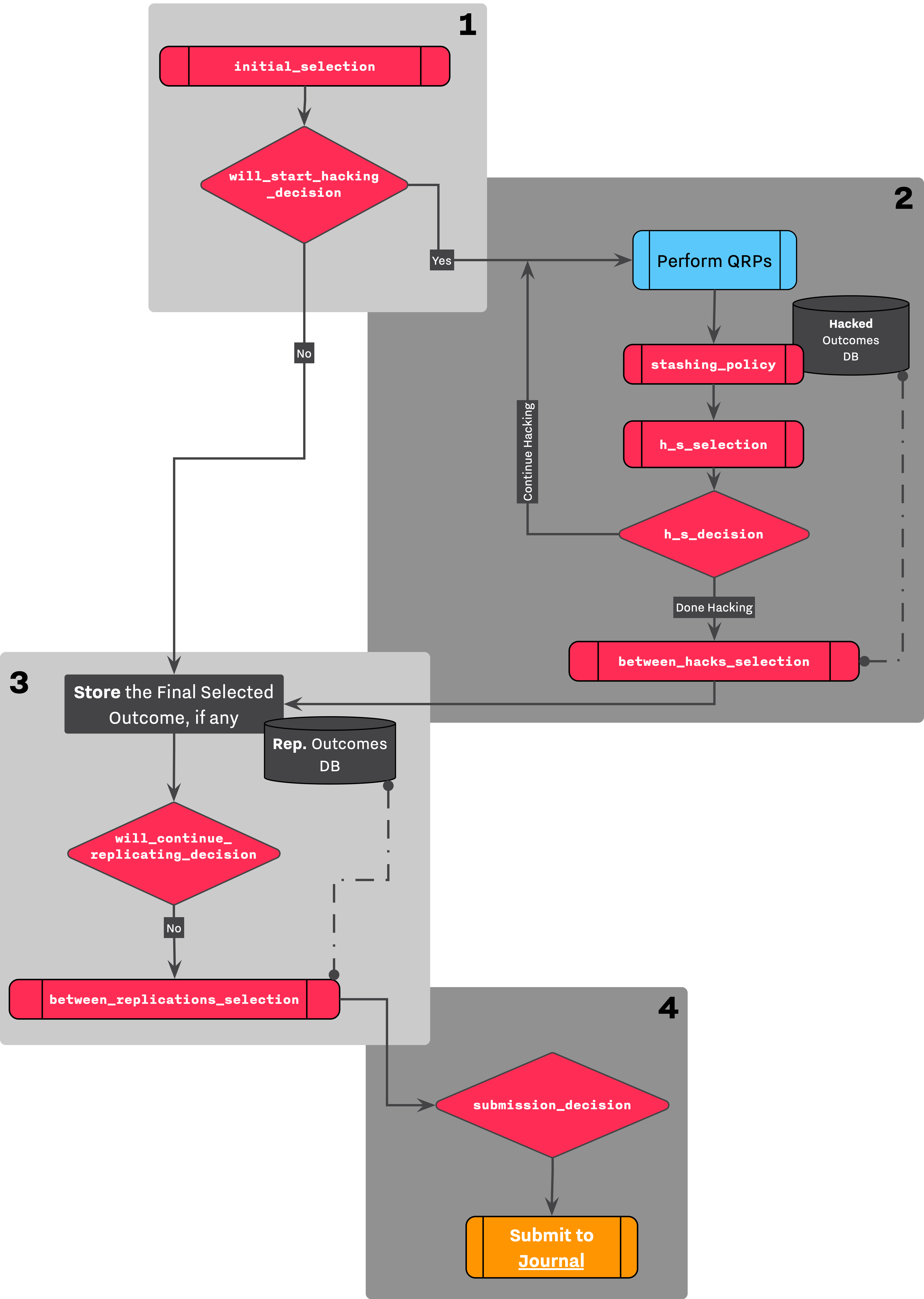
Figure 1 highlights 4 main Selection → Decision sequences of research and hackingw workflow. Here we
- Initial sequence
- Performing a selection on an original experiment
- Evaluating the selected outcome (if any) to make a decision on whether to enter the Hacking Workflow.
- While Hacking sequences
- Performing a selection on an altered experiment
- Stashing Step: Selecting certain outcomes for building a database of alternated outcomes
- Evaluating the selected outcome (if any) to make a decision on whether to continue with the rest of hacking strategies.
- Performing a selection on an altered experiment
- After Hacking sequences
- Performing a selection on the database of altered outcomes (collected during hacking workflow), stashed results.
- Evaluating the selected outcome — from the database of altered outcomes — to make a decision on whether to replicate the study.
- Before Submission sequences
- Evaluating the final submission, SF, to make decision on whether to submit the final submission to the Journal.
All possible selections and decisions steps can be found in the list below:
initial_selection_policieswill_start_hacking_decision_policiesstashing_policyh_s_selectionh_s_decision- ...
between_hacks_selection_policiesbetween_replications_selection_policieswill_continue_replicating_decision_policysubmission_decision_policies
Policies¶
Policies are the building blocks of researcher’s logic. Each policy is a logical expression describing a query to be performed on list of available outcome variables.
Here we discuss a range of available logical expression and variables that can be used to construct any elaborate quesries.
Policy¶
A policy is a string consists of a function and a variable. A function defines a kind of a query that is going to be applied on an experiment, and the variable specifies the parameter of the experiment that is going to be queried. For instance, min(pvalue) policy will query experiment’s outcomes for the outcome with the minimum p-value.
List of available functions for constructing a policy is:
min(x), returns an outcome with minimumxparameters among all outcomesmax(x), returns an outcome with maximumxparameters among all outcomesfirst, returns the first items in the listlast, returns the last items of the listsig, returns a list of significant outomcesall, returns all outcomes- uniary operator,
! - binary operators,
>,<,>=,<=,==
And list of all available parameters:
id, a unique identifier of outcome variablesnobs, number of observations associated with outcome variablesmean, the mean value associated with the outcome variablespvalue, the p-value associated with outcome variableseffect, the effect size associated with outcome variablessig, the significant flag associated with outcome variables, set by comapring pvalue against ɑ.
Any combinations of listed functions and parameters can be used to create a policy. For instance,
max(pvalue), returns an outcome variable with maximum p-valuemax(effect), returns an outcome variable with minimum effectsig, returns outcome variables that are significant!sig, returns outcome variables that are not significanteffect > 0, return outcome variables with positive effectpvalue < 0.025, return outcome variables with p-value lower than 0.025id == 5, returns outcome the outcome variable with theidset to 5.
Policy Chain, PC¶
A policy chain is a list of queries applied one after another on an experiment. They are the main mean of constructing larger and more complicated queries. For example, [“sig”, “min(pvalue)”] queries an experiment for a list of significant outcomes and among them returns the one with minimum p-value. As demonstrated, policies will be applied one after another in a hierarchal order; in fact, they should be seen as AND statements, "sig" AND "min(pvalue)", that are going to be applied on Experiments.
Important
Decision(s) are defined in term of policy chains. In fact, decisions are set of queries assessing the truth of their policies. For instance, will_start_hacking_decision_policies is helping a researcher to decide on whether to start the hacking procedure.
Policy Chain Set, PCS¶
A policy chain set is a set of policy chains. Policy chain sets are mainly being used in Selection steps. A researcher goes through every policy chain in a hierarchal order and stops as soon as one returns a unique outcome.
{
"initial_selection_policies": [
[“sig”, “min(pvalue)”],
[“effect > 0”, “min(pvalue)”],
[“effect < 0”, “first”]
]
}
For instance, research with the selection policy chain set above:
- starts by looking for
[“sig”, “min(pvalue)”] - if there is no outcome with these properties, he moves to search for
[“effect > 0”, “min(pvalue)”], - and finally, if that returns no unique outcome, he applies the last set of queries on the Experiment.
Policy chain sets are designed to mimic behaviors of a researchers with multiple priorities. An example of this behavior is demonstrated in Bakker et al., 2012 simulation.
Example: Bakker et al., 2012's Decision Strategy
{
"decision_strategy": {
"name": "DefaultDecisionMaker",
"between_hacks_selection_policies": [
["effect > 0", "min(pvalue)"],
["effect < 0", "max(pvalue)"]
],
"between_replications_selection_policies": [
["effect > 0", "sig", "first"],
["effect > 0", "min(pvalue)"],
["effect < 0", "max(pvalue)"]
],
"initial_selection_policies": [
["id == 2", "sig", "effect > 0"],
["id == 3", "sig", "effect > 0" ]
],
"stashing_policy": [
"all"
],
"submission_decision_policies": [
""
],
"will_continue_replicating_decision_policy": [""],
"will_start_hacking_decision_policies": ["effect < 0", "!sig"]
}
}